What is Big Data?
Big datais the term for
a collection of data sets so large and complex that it becomes difficult to
process using on-hand database management tools or traditional data processing
applications. The challenges include capture, curation, storage, search,sharing,
transfer, analysis and visualization. The trend to larger data sets is due to
the additional information derivable from analysis of a single large set of
related data, as compared to separate smaller sets with the same total amount
of data, allowing correlations to be found to "spot business trends,
determine quality of research, prevent diseases, link legal citations, combat
crime, and determine real-time roadway traffic conditions
What is Hadoop?
1) Hadoop is a free, Java based programing framework.
2) That supports the processing of large data sets in a
distributed computing environment.
3) Get the results faster using reliable and scalable
Architecture.
4) Hadoop's HDFS is a highly fault-tolerance distributed
file system.
Apache Hadoop is an open-source software framework for storage and large-scale processing of data-sets on clusters of commodity hardware. Hadoop is an Apache top-level project being built and used by a global community of contributors and users.It is licensed under the Apache License 2.0. Hadoop was created by Doug Cutting and Mike Cafarella in 2005.Cutting, who was working at Yahoo! at the time,named it after his son's toy elephant.It was originally developed to support distribution for the Nutch search engine project.
Apache Hadoop's MapReduce and HDFS
components originally derived respectively from Google's MapReduce and
Google File System (GFS) papers.

Imagine this scenario: You have 1GB of data that you need to process. The data are stored in a relational database in your desktop computer and this desktop computer has no problem handling this load. Then your company starts growing very quickly, and that data grows to 10GB. And then 100GB. And you start to reach the limits of your current desktop computer. So you scale-up by investing in a larger computer, and you are then OK for a few more months. When your data grows to 10TB, and then 100TB. And you are fast approaching the limits of that computer. Moreover, you are now asked to feed your application with unstructured data coming from sources like Facebook, Twitter, RFID readers, sensors, and so on. Your management wants to derive information from both the relational data and the unstructured data, and wants this information as soon as possible. This is called as Big Data.

What should you do now? Hadoop may be the answer. It is a framework written in Java originally developed by Doug Cutting who named it after his son's toy elephant. It is optimized to handle massive quantities of data which could be structured, unstructured or semi-structured, using commodity hardware, that is, relatively inexpensive computers. This massive parallel processing is done with great performance. However, it is a batch operation handling massive quantities of data, so the response time is not immediate. There are four major components of hadoop which is explained in slides.

Hadoop uses Google’s MapReduce and Google File System technologies as its foundation.

It is self-explanatory slide. However, in a brief, Imagine you want to process 1 TB of data using your laptop, it will take approximately 45 minutes. But, if you want to process the data using 10 machines running in parallel then that process will take 4.5 minutes because job is divided into 10 identical machines each running concurrently.

Hadoop is a master-slave architecture. Hadoop’s has a file
system called as HDFS (Hadoop distributed file system) which is used to store
files and data. Similar to our laptop harddisk file system which uses NTFS or
FAT system to store the data. Hadoop’s file system has a namenode which is
master and datanode as it’s slave. Ignore, jobtracker and tasktracker, we will
not discuss in details. However, both are integral part of hadoop map reduce.

Namenode is heart of HDFS. It is single point of failure, it
means that if it goes down, everything goes down. It is used to store metadata.
It tells the client that where exactly data is stored in HDFS. It is basically
a pointer which is used to tell the file location, it’s date of creation, it’s
size and all the file related information. There is only one namenode per
cluster.
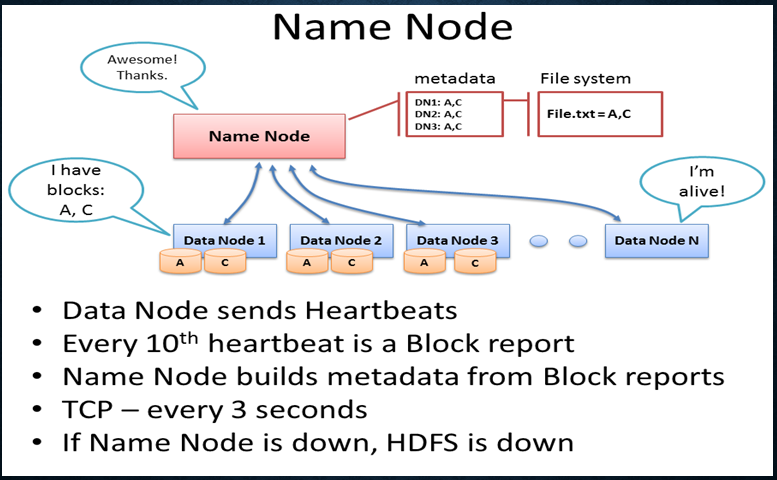
To store the data in HDFS, a file is divided into chunks
called as blocks (usually block size is 64 MB or 128 MB). Now these blocks are
stored inside a datanode (think datanode as harddisk). Therefore, there is a
possibility that hard disk or datanode may fail. This, How namenode will come
to know? Here is the dirty trick, datanode
sends heartbeat to name node every three seconds and a block report
(information pertaining to which blocks it is currently storing) every 10
seconds. If it stops sending heartbeat, then name node will consider datanode
as faulty and restores its block in some other datanode based on the block
report it received from that failed datanode.

Secondary NameNode

What if name node itself goes down? There is another name node called as secondary name node which is used as house keeping, back up for name node. It does not means that it can replace name node at time of its failure. It is just a clone which has information about what metadata name node is currently storing.
Secondary NameNode
What if name node itself goes down? There is another name node called as secondary name node which is used as house keeping, back up for name node. It does not means that it can replace name node at time of its failure. It is just a clone which has information about what metadata name node is currently storing.
Suppose, I want to write a file.txt which is too large in
size. First, that file.txt is divided into blocks as discussed earlier. Suppose
there are three blocks. Now, client will ask namenode where can I (client)
store this file. Namenode then says, ok write it to datanode 1,5 and 6. Now,
client will go to data node 1 and writes the file (it’s blocks), then to
datanode 5 and finally to datanode 6. (It is worth to note that HDFS will write
the same file three times but in different location to maintain replication
factor as 3 so that in case of failure HDFS can retrieve the data). After,
writing completion, the datanode 6 will send the success signal to data node 5
and then to data node 1. Data node 1 then sends success signal to client which
further tells the success to namenode.
However, it is possible that the blocks of the same file can
be stored in different location which will occur frequently in hadoop.


In order to read a file, client will ask name node to I want the file say result.txt. Name node will then reply that ok, there are three blocks (blk a, blk b, blk c) of the file result.txt. Block is stored in location 1, 5 and 6. Client will then go to location 1 and will get the block. (Incase, if client is not able to retrieve the block then it will go to the next location 5 to retrieve the block). Similar is the case with blk b and blk c. This is how read operation is performed in HDFS.
Advantages with
Hadoop/Big Data: 5 Major Advantages for hadoop?
Scalable
Hadoop is a highly scalable storage platform,
because it can store and distribute very large data sets across hundreds of
inexpensive servers that operate in parallel. Unlike traditional relational
database systems (RDBMS) that can't scale to process large amounts of data,
Hadoop enables businesses to run applications on thousands of nodes involving
thousands of terabytes of data.
Cost effective
Flexible
Data sources such as social media, email
conversations or clickstream data. In addition, Hadoop can be used for a wide
variety of purposes, such as log processing, recommendation systems, data
warehousing, market campaign analysis and fraud detection.
Fast
Resilient to failure
A key advantage of using
Hadoop is its fault tolerance. When data is sent to an individual node, that
data is also replicated to other nodes in the cluster, which means that in the
event of failure, there is another copy available for use.
Hadoop Distribution File System
· The Hadoop Distributed
File System (HDFS) is a distributed file system designed to run on commodity
Hardware and also it’s storage system used by Hadoop.HDFS is highly fault
–tolerant and is HDFS contains two main components and those two comes under
DFS Category.
·
Name Node ( Meta Data)
·
Data Node ( Actual Data)

Diagram:

Some key points to remember about hadoop.
· In the above diagram,
there is one NameNode, and Multiple DataNodes(Servers). b1, b2, indicates the data blocks.
·
When you dump a file (or
Data) into the HDFS, it stores them in blocks on the various nodes in the
hadoop cluster. HDFS creates several replication of the data block and
distributes them accordingly in the cluster in a way that will be reliable and
can be retrieved faster. A typical HDFS block size is 128 MB.Each and every
block in the cluster replicated to multiple nodes across the cluster.
● Hadoop will internally make sure that any
node failure will never results in a data loss.
● There will be One NameNode that manages the file
system metadata.
● There will be multiple DataNodes( These are the
real cheap commodity servers) that will stores the data blocks.
● When you execute a query from a client, it will
reach out to the NameNode to get the file metadata information and then it will
reach out to the DataNodes to work on HDFS.
● The NameNode comes with an in-built web server
from where you can browse the HDFS file system and view some basic cluster
statistics.Hadoop provides a command line interface for administration to work
on HDFS

Job Tracker : Manages
cluster resources and job scheduling and manages the job cycle of the cluster
Task Tracker :Per-node
agent & Manage tasks.
MapReduce:
● MapReduce
is a parallel programming model that is used to retrieve the data from the
Hadoop Cluster.
● Map reduce is an
algorithm or concept to process Huge amount of data in a faster way. As per its name you can divide it Map and
Reduce
● The main MapReduce job
usually splits the input data-set into independent chunks. (Big data sets in the multiple small datasets)
● In this
model, the library handles lot of messy details that programmers doesn’t need
to worry about. For Example, the library takes care of parallelization, fault
tolerance, data distribution, load balancing, etc.
● This splits
the tasks and executes on the various nodes parallel thus speeding up the
computation and retrieving required data from a huge dataset in fast manner.
● This
provides a clear abstraction for programmers they have to just implement (or
use) two functions: map and reduce.
● The data
are fed into the map function as key value pairs to produce intermediate
key/value pairs.
● Once the
mapping is done, all the intermediate results from various nodes are reduced to
create the final output.
● Job
Tracker:
● Is the
daemon service for submitting and tracking MapReduce jobs in Hadoop.
● There is
only one job tracker process run on any hadoop cluster.
● Job Tracker
runs on its own JVM process.
● Each slave
node is configured with job tracker node location.
● Job Tracker
is a single point of failure for the hadoop MapReduce Service.it it goes down
all the running jobs halted.
● Job Tracker
performs the below actions.
● Client
Applications submit jobs to the job tracker.
● The Job
Tracker talks to the NameNode to determine the location of the data.
● The Job
Tracker locates Task Tracker nodes with available slots at or near the data.
● The Job
Tracker submits the work to the chosen Task Tracker nodes.
● The Task
Tracker nodes are monitored. If they don’t submit heartbeat signals often
enough, they are deemed to have failed and the work is scheduled on a different
Task Tracker.
● keeps track
of all the MapReduces jobs that are running on various nodes.This schedules the
jobs,keeps track of all the map and reduce jobs running across the nodes. If
any one of those jobs fails , it reallocates the job to another node etc.
Simply job tracker is the responsible for making sure that the query on a huge
dataset runs successfully and the data is returned to the client in a reliable
manner.
● Task
Tracker performs the map and reduce tasks that are assigned by the Job Tracker.
Task Tracker also constantly sends a heartbeat message to Job Tracker . which
helps Job Tracker to decide whether to delegate a new task to this
particular node or not.
Hadoop
Web Interfaces:
Hadoop comes with several web Interfaces which are by
default (see conf/hadoop-default.xml) available at these locations.
These web interfaces provide concise information about
what’s happing in your Hadoop cluster.
NameNode
Web Interface (HDFS layer):
●
The
Name Node web UI shows you a Cluster summary including information about
Total/Remaining capacity, live and dead nodes.
●
Additionally,
it allows you to brows the HDFS namespace and view the contents of its files in
the Web browser.
●
It
also gives access to the Hadoop log files.

JobTracker
Web Interface (MapReduce Layer):
●
Job
Tracker is the daemon service for submitting and tracking MapReduce jobs in
Hadoop.
●
There
is only one Job Tracker process run on any hadoop cluster and it’s run on it’s
own JVM process.
●
The
JobTracker Web UI Provides information about general job statistics of the
Hadoop cluster, running/completed/failed jobs and a job history log file.
●
It
also gives access to the “Local machine’s” Hadoop log files( the machine on
which the web UI is running on).
TaskTracker
Web Interface (MapReduce Layer):
The
task tracker web UI shows you running and non-running tasks. It also gives
access to the “local machine’s” Hadoop log files
No comments:
Post a Comment